Explore
Featured
Recent
Articles
Topics
Login
Upload
Featured
Recent
Articles
Topics
Login
Upload
Search Results for 'visual feature'
visual feature published presentations and documents on DocSlides.
What is a visual text? Where do you find them?
by myesha-ticknor
What feature is the focus?. Who is the audience?....
Getting funded Getting funded
by beatrice
If at first you don’t succeed. How the process w...
Audio Feature Representations
by giovanna-bartolotta
Detecting Semantic Concepts In Consumer Videos Us...
Upcoming Stuff:
by liane-varnes
Finish attention lectures this week. No class Tue...
Visual Pattern Recognition
by liane-varnes
Taylor J. Meek. October 22, 2009. Evidence and Co...
Learning to Judge
by myesha-ticknor
Image Search Results. for Synonymous Queries. Nat...
Fundamentals of Sensation and Perception
by conchita-marotz
Attention and awareness. Erik Chevrier. September...
Modeling visual clutter using proto-objects
by myesha-ticknor
Tech Talk @ . shutterstock. . . Presenter: . ...
Modeling visual clutter using proto-objects
by danika-pritchard
Tech Talk @ . shutterstock. . . Presenter: . ...
Chapter 6 Visual AttentionEveryone knows what attention is It is th
by catherine
http://viscog.beckman.uiuc.edu/grafs/demos/15.html...
Recognition - III General recipe
by wilson
Fix . hypothesis class. Define . loss function. Mi...
Addressing the Medical Image Annotation Task using visual words representation
by danya
Uri Avni , Tel Aviv University, Israel. Hayit. ...
Attention and Consciousness
by kylie
Divided Attention. Selective Attention. Theories o...
SUPER: Towards Real-time Event Recognition in Internet Vide
by alexa-scheidler
Yu-Gang . Jiang. School of Computer Science. Fuda...
3 – Selective Attention
by myesha-ticknor
. selective attention. attending to part ...
Microsoft Visual Studio Team
by luanne-stotts
System Team Foundation Server: . How We Use It at...
6.S093 Visual Recognition through Machine Learning Competit
by trish-goza
. Image by kirkh.deviantart.com. Aditya. . Khos...
Scalable Visual Instance Mining with Threads of Features
by davis
Wei Zhang, . Hongzhi Li. , Chong-Wah Ngo, Shih-Fu ...
Carl
by tatiana-dople
Callewaert & Adam Tuliper. Unity / Microsoft....
How Do You Tell a Blackbird from a Crow?
by olivia-moreira
Thomas Berg and Peter N. . Belhumeur. Columbia Un...
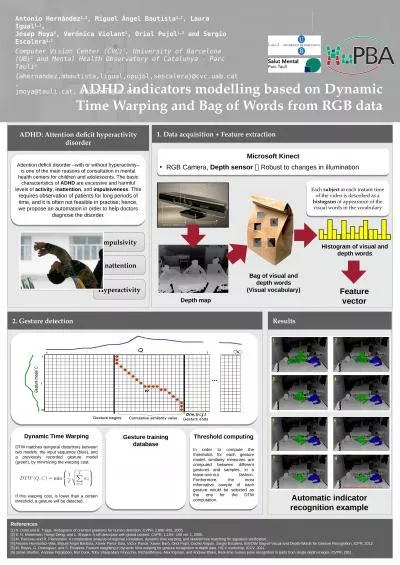
Antonio Hernández 1,2 , Miguel
by reagan
Ángel. Bautista. 1,2. , Laura Igual. 1,2. ,. Jos...
Introduction to recognition
by maniakti
Source: . Charley Harper. Outline. Overview of rec...
Martin Woodward Phil Haack
by min-jolicoeur
Principal Program Manager Engineering Manager. M...
Automated Lip reading technique for people with speech disa
by faustina-dinatale
visemes. into direct speech using image processi...
ForeSight
by kittie-lecroy
: Mapping Vehicles in Visual Domain and Electroni...
Introduction to object recognition
by phoebe-click
Slides adapted from . Fei-Fei. Li, Rob Fergus, A...
The following Feature Articles by Edward Fenno and the Carolina Arts logo graphics and information are republishe d by permission of Carolina Arts a newspaper covering the visual arts in North and So
by calandra-battersby
Fennos former employer The Carolina Arts Web site...
Learning Convolutional Feature Hierarchies for Visual Recognition Koray Kavukcuoglu Pierre Sermanet YLan Boureau Karol Gregor Micha el Mathieu Yann LeCun Courant Institute of Mathematical Science
by liane-varnes
nyuedu mmathieuclipperensfr Abstract We propose an...
ccer Video based on Goalmouth Zhao Zhao, Qingming Huang, Qixiang YeIns
by kittie-lecroy
Highlight candidates generation Visual Feature ab...
ForeSight
by kittie-lecroy
: Mapping Vehicles in Visual Domain and Electroni...
Semantic Embedding Space for Zero Shot Action Recognition
by calandra-battersby
Xun. . Xu. Timothy. . Hospedales. Shaogang. Go...
Presenter:
by yoshiko-marsland
Yupu. Zhang, . Guoliang. Jin, . Tuo. . Wang. C...
Building Text features for object image classification
by olivia-moreira
Gang Wang Derek . Hoeim. David ...
Sharing Features Between Visual Tasks at Different Levels o
by giovanna-bartolotta
Sung . Ju. Hwang. 1. , . Fei. Sha. 2. and Kris...
Load More...